Unlocking the Potential of Machine Learning at the Edge: Challenges and Future Trends
TODO obrazki
Training highly accurate models on resource-constrained devices is an escalating challenge, particularly as the proliferation of edge devices continues to accelerate every year. Poor performance of AI models may be caused by issues with centralized systems and a lack of scalability on limited devices. The deployment of advanced models becomes more difficult and expensive as a result of these devices' frequently imposed limitations on their capabilities and features. This blog seeks to examine cutting-edge solutions, show practical use cases, delve into the difficulties associated with machine learning at the edge, and throw light on current trends and potential future directions in this fascinating area.
Challenges/solutions
The constraints of computation are one of the main issues. When dealing with enormous datasets or complicated models, centralized systems and devices with limited resources sometimes have scalability issues, which also demonstrates a need for developing optimization methods that can reduce the model's complexity while maintaining high metrics. The use of distributed systems to assure scalability and load balancing, model partitioning, parallelization utilizing multiprocessing libraries, and maintaining privacy with the user’s data using techniques such as Federation Learning and security approaches have been suggested by researchers as ways to get around problems. Additionally, federated learning has demonstrated the potential in resolving this issue, allowing models to be trained cooperatively across numerous devices without disclosing sensitive data 1 2 3 4. The necessity of resource optimization, privacy-preserving algorithms, and bias mitigation methods is highlighted while also discussing optimization strategies and security measures 5.
Real-World Use Cases
A wide number of sectors are included in machine learning at the edge, including, among others, autonomous driving, entertainment, healthcare, power use, video analytics, smart agriculture, and smart cities. These use cases demonstrate the enormous potential of edge-based machine learning, where even little mistakes can have negative effects. The realization of this potential enables efficient and real-time data analysis and decision-making by overcoming obstacles including constrained bandwidth, decreased latency, and the optimization of specialized operating systems created especially for edge devices 6 7 8.
Why an Intelligence Layer in ICOS?
In data-intensive edge/cloud applications, the intelligence layer makes it easier to train, test, deploy, and maintain machine learning models. It has modules for coordinating, processing data, analyzing AI, storing model data on the ICOS repository, and ensuring reliable AI using federated learning and trustable AI constraints. These modules work together to maximize the use of models, enable large-scale data processing, train predictive models, store previously trained models, protect data privacy, and assure model explainability. Most importantly, this prototypes how other dedicated operative systems for the edge could integrate in an effective way their scalability and full potential using AI.
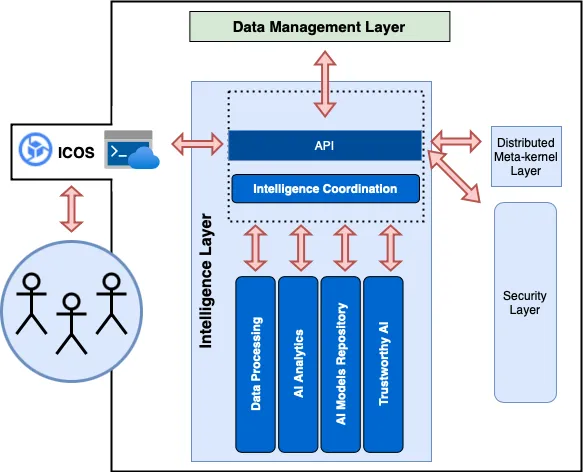
Figure 1: Interactions of the Intelligence Layer Coordination Module
Conclusion
As a result, the creation and incorporation of an AI layer into ICOS have highlighted important drawbacks and difficulties related to machine learning at the edge while also offering workable ways to strengthen this operating system. It has also been possible to spot new trends in the industry thanks to the practical use cases. The Intelligence Layer is crucial in expediting data processing, simplifying the creation of robust models, while providing model repository capabilities, and maintaining trustworthiness through privacy protection and explainability through the integration of multiple modules and features. This all-encompassing strategy aims to enhance machine learning's edge capabilities and unleash its full potential within the ICOS ecosystem.
Footnotes
- C. P. Filho, E. Marques, V. Chang, L. dos Santos, F. Bernardini, P. F. Pires, L. Ochi, and F. C. Delicato, “A Systematic Literature Review on Distributed Machine Learning in Edge Computing,” Sensors, vol. 22, no. 7, 2022.Online. Available: https://www.mdpi.com/1424-8220/22/7/2665 ↩
- D. Xu, T. Li, Y. Li, X. Su, S. Tarkoma, T. Jiang, J. Crowcroft, and P. Hui, “Edge Intelligence: Architectures, Challenges, and Applications,” 3 2020. Online. Available: https://arxiv.org/abs/2003.12172v2 ↩
- Z. Zhou, X. Chen, E. Li, L. Zeng, K. Luo, and J. Zhang, “Edge Intelligence: Paving the Last Mile of Artificial Intelligence With Edge Computing,” Proceedings of the IEEE, 2019. ↩
- G. Plastiras, M. Terzi, C. Kyrkou, and T. Theocharidcs, “Edge Intelli- gence: Challenges and Opportunities of Near-Sensor Machine Learning Applications,” in Proceedings of the International Conference on Application-Specific Systems, Architectures and Processors, vol. 2018- July. Institute of Electrical and Electronics Engineers Inc., 8 2018 ↩
- L. Qi, C. Hu, X. Zhang, M. R. Khosravi, S. Sharma, S. Pang, and T. Wang, “Privacy-Aware Data Fusion and Prediction with Spatial- Temporal Context for Smart City Industrial Environment,” IEEE Trans- actions on Industrial Informatics, vol. 17, no. 6, pp. 4159–4167, 6, 2021. ↩
- A. Rudenkc’, P. Reiher, G. J. Popek ’ ̃, and G. H. Kuenning, “Saving portable computer battery power through remote process execution,” ACM SIGMOBILE Mobile Computing and Communications Review, vol. 2, no. 1, pp. 19–26, 1 1998. Online. Available: https://dl.acm.org/doi/10.1145/584007.584008 ↩
- Y. Liu, Y. S. Wang, S. P. Xu, W. W. Hu, and Y. J. Wu, “Design and Implementation of Online Monitoring System for Soil Salinity and Alkalinity in Yangtze River Delta Tideland,” 2021 IEEE International Conference on Artificial Intelligence and Industrial Design, AIID 2021, pp. 521–526, 5 2021. ↩
- M. Sapienza, E. Guardo, M. Cavallo, G. La Torre, G. Leombruno, and O. Tomarchio, “Solving Critical Events through Mobile Edge Computing: An Approach for Smart Cities,” 2016 IEEE International Conference on Smart Computing, SMARTCOMP 2016, 6 2016. ↩




This project has received funding from the European Union’s HORIZON research and innovation programme under grant agreement No 101070177.