Leveraging Federated Learning in the ICOS continuum
Federated Learning (FL) has recently emerged as a computationally efficient solution in highly complex machine learning (ML) scenarios, where data should be collected from various and diverse sources. In this context, instead of transmitting all related information to a centralized location, training is performed locally in all participating nodes. Afterwards, the updated model parameters (e.g., weights in a neural network or clustering/vector parameters in k-NN/SVM models) are send to the master node for model aggregation. At the final stage, the updated parameters are send back to the participating nodes to be included in local ML models. Hence, this approach not only leverages distributed computations and thus latency minimization (data preprocessing is no longer required in the centralized node), but also privacy concerns mitigation since actual data remain localized to their sources.
The overall architectural approach of FL is depicted in Fig. 1. The master model can be either periodically updated or in cases of new training rounds in the participating nodes due to significant events.
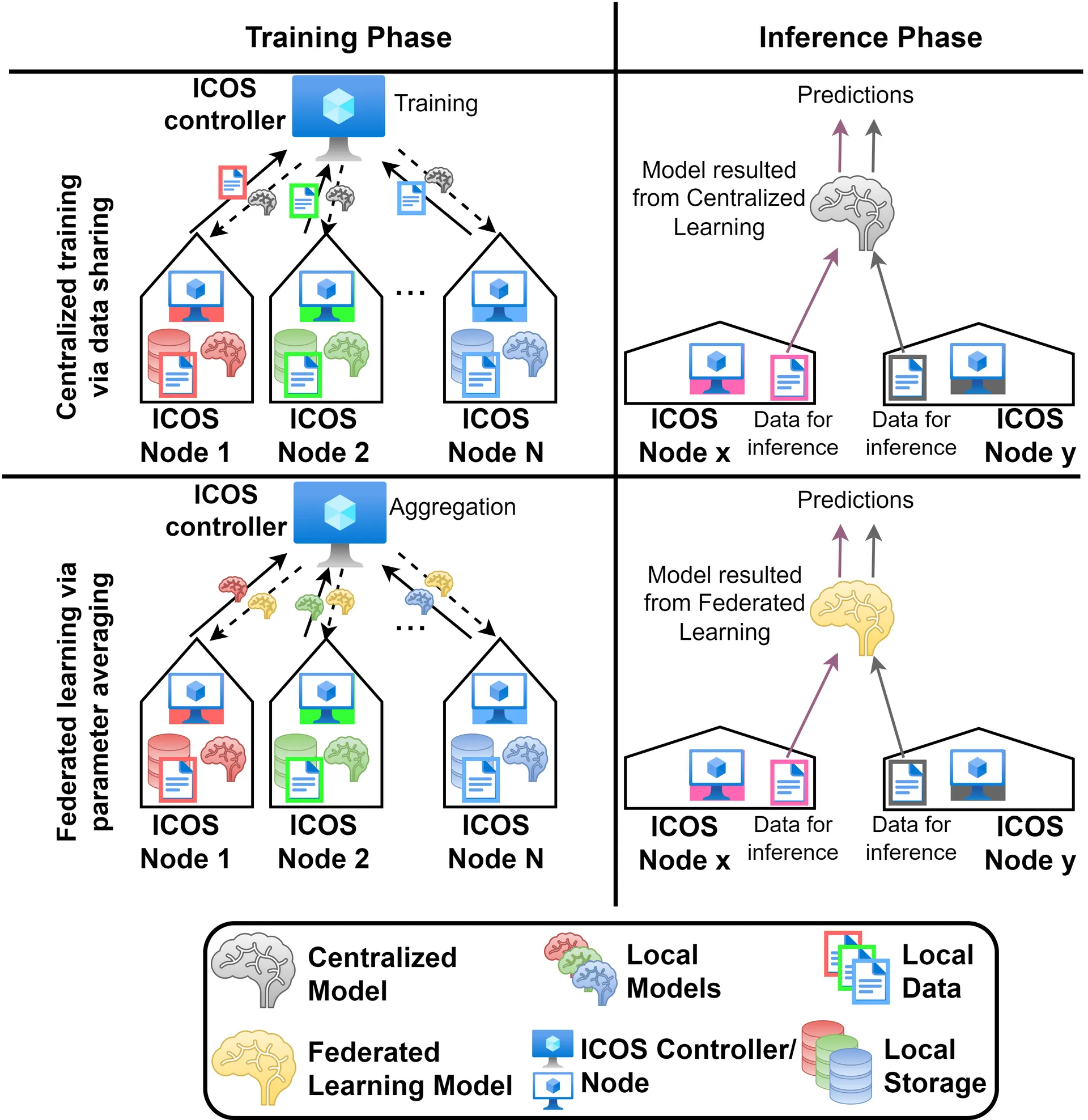
Figure 1: Architectural approach
In the framework of ICOS, there are two challenging approaches related to FL: The first one is the proper deployment of FL in the involved uses cases, such as in the fourth use case, Energy Management and Decision Support System (EMDSS). To this end, the goal is to aggregate data from various consumers of electrical energy and come up with a credible system that can accurately predict future power consumption. The second one is related to the proper selection of the involved ICOS nodes that can be used for local training and thus computational disaggregation and latency minimization. In the first case, reinforcement learning (RL) can be used for local model training, which is based on appropriate rewards or penalties based on a predetermined action space (Q-learning approach, where the outcome can be for example the selection of time intervals where each user can be treated either as a consumer or producer of electrical energy). Afterwards, due to the relatively large space of states/actions, an appropriate neural network (NN) is trained that can predict the next possible action that maximizes overall reward 1. FL can significantly reduce training times, since due to the distributed nature of this approach a large amount of data coming from independent and diverse sources can be directly incorporated into the aggregated model.
Footnotes
- A. Giannopoulos, S. Spantideas, N. Kapsalis, P. Karkazis and P. Trakadas, "Deep Reinforcement Learning for Energy-Efficient Multi-Channel Transmissions in 5G Cognitive HetNets: Centralized, Decentralized and Transfer Learning Based Solutions," in IEEE Access, vol. 9, pp. 129358-129374, 2021, doi: 10.1109/ACCESS.2021.3113501. ↩




This project has received funding from the European Union’s HORIZON research and innovation programme under grant agreement No 101070177.