Novel data and processing approaches for the development of hyper-distributed applications
Let us begin this post by clarifying its title; most of the readers right now will be thinking what are hyper-distributed applications?
Generally, most folks in the IT industry have a clear idea of what distributed applications are: one application running at the same time on different nodes of a cluster cooperating by the exchange of messages over a stable network. But then, what does the hyper stand for? With the advance of the clouds and scientific grids, the concept of distributed computing has evolved; the cluster has become a multi-source, geographically distributed infrastructure and the interconnection is no longer a secure and fast LAN network but the Internet over any kind of networking technology (optical fibre, 5G, …). As a result of this evolution, the development of efficient applications targeting these distributed infrastructures has grown more and more complicated.
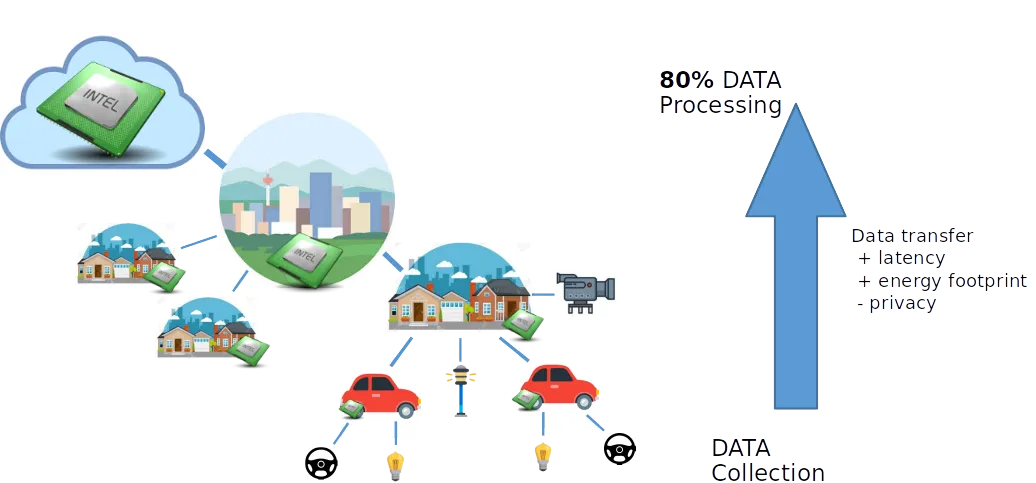
The Cloud-Edge-IOT (CEI) Continuum is a paradigmatic example of these new distributed systems; however, the performance achieved with its exploitation is still far away from what was expected. Although most of the data is being collected at the IoT level, 80% of the processing happens in a distant server on the Cloud. This model implies a constant communication of large amounts of data from IoT to the Cloud. On the one hand, the long latencies of these networks limit the potential of the infrastructure to host new business opportunities; on the other, it incurs a significant energy footprint. Besides, don’t we all have concerns about the privacy of all the data we are pushing into the cloud?
With some imagination, we can foresee different scenarios where this Cloud Computing model falls short. Let's think of an IoT sensor noticing something that requires the infrastructure to give a proper response (sense-process-actuate scenario). IoT devices have little computing capability; hence, to overcome this scarcity and trigger a proper response to such an event, the Cloud proposes launching a Function-as-a-Service execution on a cloud server. However, with proper continuum management, this computation could be offloaded onto a nearby edge server to reduce the latency of the response and the energy consumed in the networking. The same approach could be followed when, instead of reacting to an event, the application processes continuous sources of data (stream processing).
Another scenario, closer to traditional distributed computing, is batch jobs executed upon a request by users or by scheduled computations; for instance, a system administrator running a large dataset analysis to train a Machine Learning algorithm. To do so, current solutions collect all the data on the cloud where it will be processed. However, approaches such as federated learning propose a more efficient solution where, instead of transferring all the data, it is kept on the device that collects it (or a closer edge server) and the cloud sends the computation to that device and collects only the result. This not only improves the energy efficiency of the technology but also removes any privacy concerns from the end users of the application.
Hyper-distributed applications require new approaches and frameworks that ease their development while keeping an efficient operation. Not only because of the evolution of the infrastructure, passing from a static system with proactive management growing or shrinking the resource pool to a dynamic environment where mobile components enforce reactive management with forecasting capabilities; but also, because the execution model has changed. Applications will no longer consist in one single host node where the computation is triggered and that generates a computational workload to be distributed across the infrastructure. In hyper-distributed applications deployed on the Continuum, every node becomes a potential source of workload; several workflows can be triggered at the same time and the resources must be shared among all of them. These changes deprecate the coordinator-worker execution model, followed by most of the state-of-the-art frameworks for the development of distributed applications, and pave the way for a new generation of software working in a peer-to-peer manner where workload and data orchestration becomes a shared responsibility.
At the Barcelona Supercomputing Center, we embraced this change of philosophy and adapted our tools for data management (dataClay) and distributed workflows (COMPSs) for HPC systems to ease the development of hyper-distributed applications in the CEI Continuum. The ICOS project will adopt both tools as part of the meta-OS and leverage the experience obtained through that process to develop the Data and Runtime Management functionalities.




This project has received funding from the European Union’s HORIZON research and innovation programme under grant agreement No 101070177.